input{
beats{
port => 5044
}
}
output{
kafka {
#输出到卡夫卡
bootstrap_servers => "172.16.0.45:9092,172.16.0.46:9092,172.16.0.47:9092"
#主题名称
topic_id => ["mrobot-log"]
codec => json
}
}
#验证
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/collect.conf -t
systemctl restart logstash
systemctl enable logstash
filebeat.inputs:
#mrobot-server
#debug
- type: log
#开启采集
enabled: true
#标签
tags: ["mrobot-server-debug"]
#日志路径
paths:
- /mrobot-server/logs/log_debug.log
#添加字段
fields:
host_ip: 172.16.1.13
#新建字段放在顶级
fields_under_root: true
exclude_lines: ["^$"]
output.logstash:
hosts: ["172.16.0.48:5044"]
enabled: true
#工作线程数
worker: 4
#压缩机别
comperssion_level: 3
processors:
#删除无用数据
- drop_fields:
fields: ["input", "ecs", "agent", "host", "log"]
root@es-01:~# cat /etc/logstash/conf.d/handle.conf
input {
kafka {
#指定卡夫卡服务器
bootstrap_servers => "172.16.0.45:9092,172.16.0.46:9092,172.16.0.47:9092"
#logstash集群消费kafka集群的身份标识,必须集群相同且唯一
group_id => "logstash-handle"
#要消费的kafka主题,logstash集群相同
topics => ["mrobot-log"]
#消费线程数,集群中所有logstash相加最好等于 topic 分区数
consumer_threads => 17
#禁止插入元数据字段
decorate_events => false
#kafka消费策略,已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
auto_offset_reset => "earliest"
#定义type方便后面选择过滤及输出
type => "mrobot-log"
#保持json格式
codec => json
}
}
filter {
#处理日期时区问题
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
#移除多余tag
mutate {
remove_tag => ["beats_input_codec_plain_applied"]
}
}
output {
if [type] == "mrobot-log" {
elasticsearch {
hosts => ["172.16.0.45:9200","172.16.0.46:9200","172.16.0.47:9200"]
#禁止使用模板
manage_template => false
index => "%{host_ip}-%{tags}-%{+YYYY.MM.dd}"
}
}
}
#验证
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/handle.conf -t
systemctl restart logstash
systemctl enable logstash
在以上整个架构中,核心的几个组件Kafka、Elasticsearch、Hadoop天生支持高可用,唯独Logstash是不支持的,用单个Logstash去处理日志,不仅存在处理瓶颈更重要的是在整个系统中存在单点的问题,
如果Logstash宕机则将会导致整个集群的不可用,后果可想而知。
如何解决Logstash的单点问题呢?我们可以借助Kafka的Consumer Group来实现。
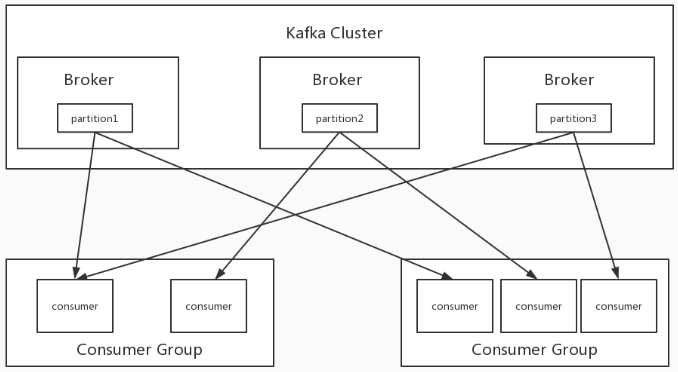
Consumer Group: 是个逻辑上的概念,为一组consumer的集合,同一个topic的数据会广播给不同的group,同一个group中只有一个consumer能拿到这个数据。也就是说对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个consumer消费,基于这一点我们只需要启动多个logstsh,并将这些logstash分配在同一个组里边就可以实现logstash的高可用了。
logstash消费kafka集群的配置中,其中加入了group_id参数,group_id是一个的字符串,唯一标识一个group,具有相同group_id的consumer构成了一个consumer group,这样启动多个logstash进程,只需要保证group_id一致就能达到logstash高可用的目的,一个logstash挂掉同一Group内的logstash可以继续消费。除了高可用外同一Group内的多个Logstash可以同时消费kafka内topic的数据,从而提高logstash的处理能力。
但需要注意的是消费kafka数据时,每个consumer最多只能使用一个partition,当一个Group内consumer的数量大于partition的数量时,只有等于partition个数的consumer能同时消费,其他的consumer处于等待状态。例如一个topic下有3个partition,那么在一个有5个consumer的group中只有3个consumer在同时消费topic的数据,而另外两个consumer处于等待状态,所以想要增加logstash的消费性能,可以适当的增加topic的partition数量,但kafka中partition数量过多也会导致kafka集群故障恢复时间过长,消耗更多的文件句柄与客户端内存等问题,也并不是partition配置越多越好,需要在使用中找到一个平衡。
Logstash的input读取数的时候可以多线程并行读取,logstash-input-kafka插件中对应的配置项是consumer_threads,默认值为1。一般这个默认值不是最佳选择,那这个值该配置多少呢?这个需要对kafka的模型有一定了解:
kafka的topic是分区的,数据存储在每个分区内;
kafka的consumer是分组的,任何一个consumer属于某一个组,一个组可以包含多个consumer,同一个组内的consumer不会重复消费的同一份数据。所以,对于kafka的consumer,一般最佳配置是同一个组内consumer个数(或线程数)等于topic的分区数,这样consumer就会均分topic的分区,达到比较好的均衡效果。
举个例子,比如一个topic有n个分区,consumer有m个线程。那最佳场景就是n=m,此时一个线程消费一个分区。如果n小于m,即线程数多于分区数,那多出来的线程就会空闲。
如果n大于m,那就会存在一些线程同时消费多个分区的数据,造成线程间负载不均衡。
查看分区数