[TOC]
PromQL (Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力非常丰富,内置函数很多,在日常数据可视化以及rule 告警中都会使用到它。
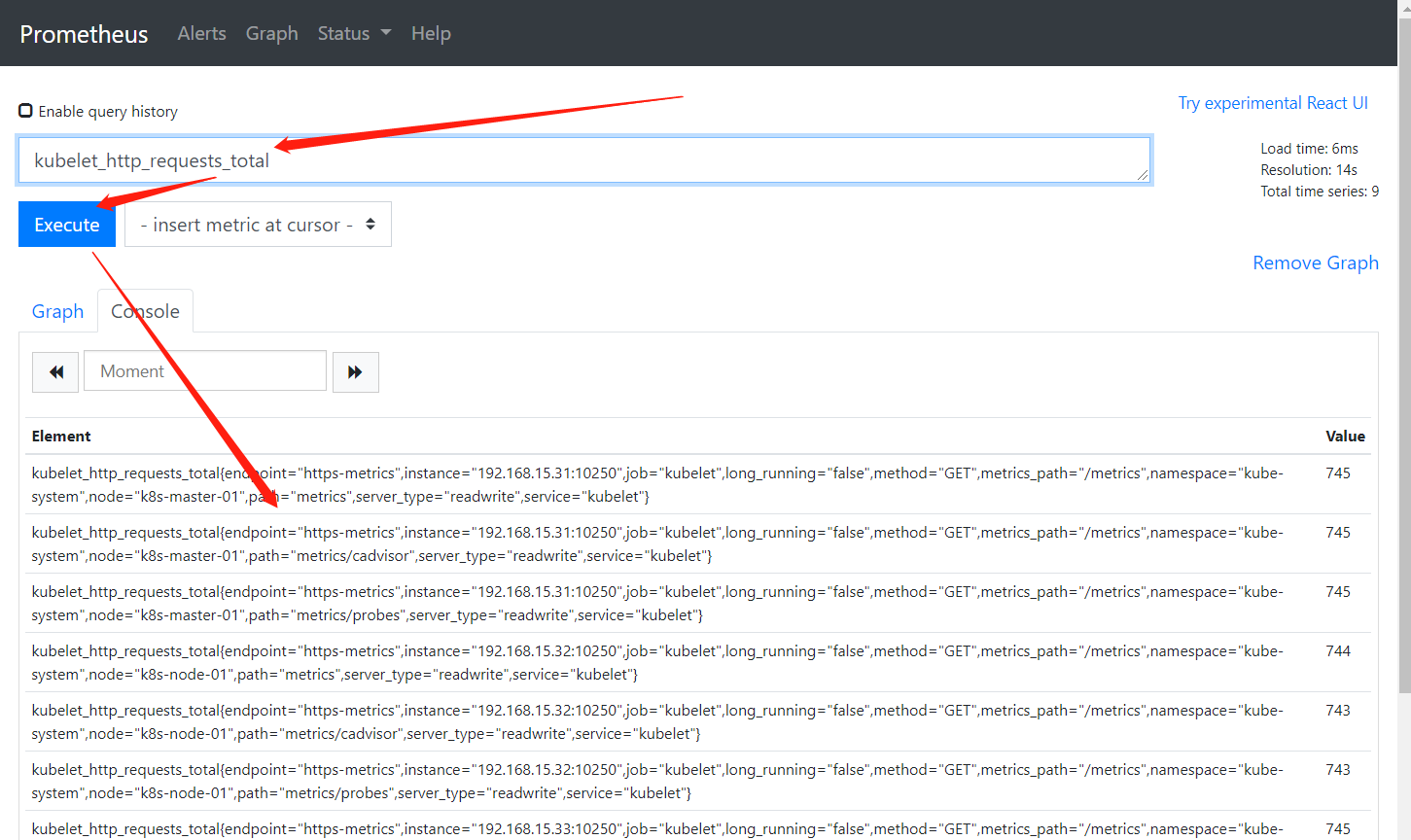
在页面 http://localhost:9090/graph 中,输入下面的查询语句,查看结果,例如:
PromQL 查询结果主要有 3 种类型:
1、瞬时数据(Instant vector): 包含一组时序,每个时序只有一个点
2、区间数据(Range vector): 包含一组时序,每个时序有多个点
3、纯量数据(Scalar): 纯量只有一个数字,没有时序
kubelet_http_requests_total
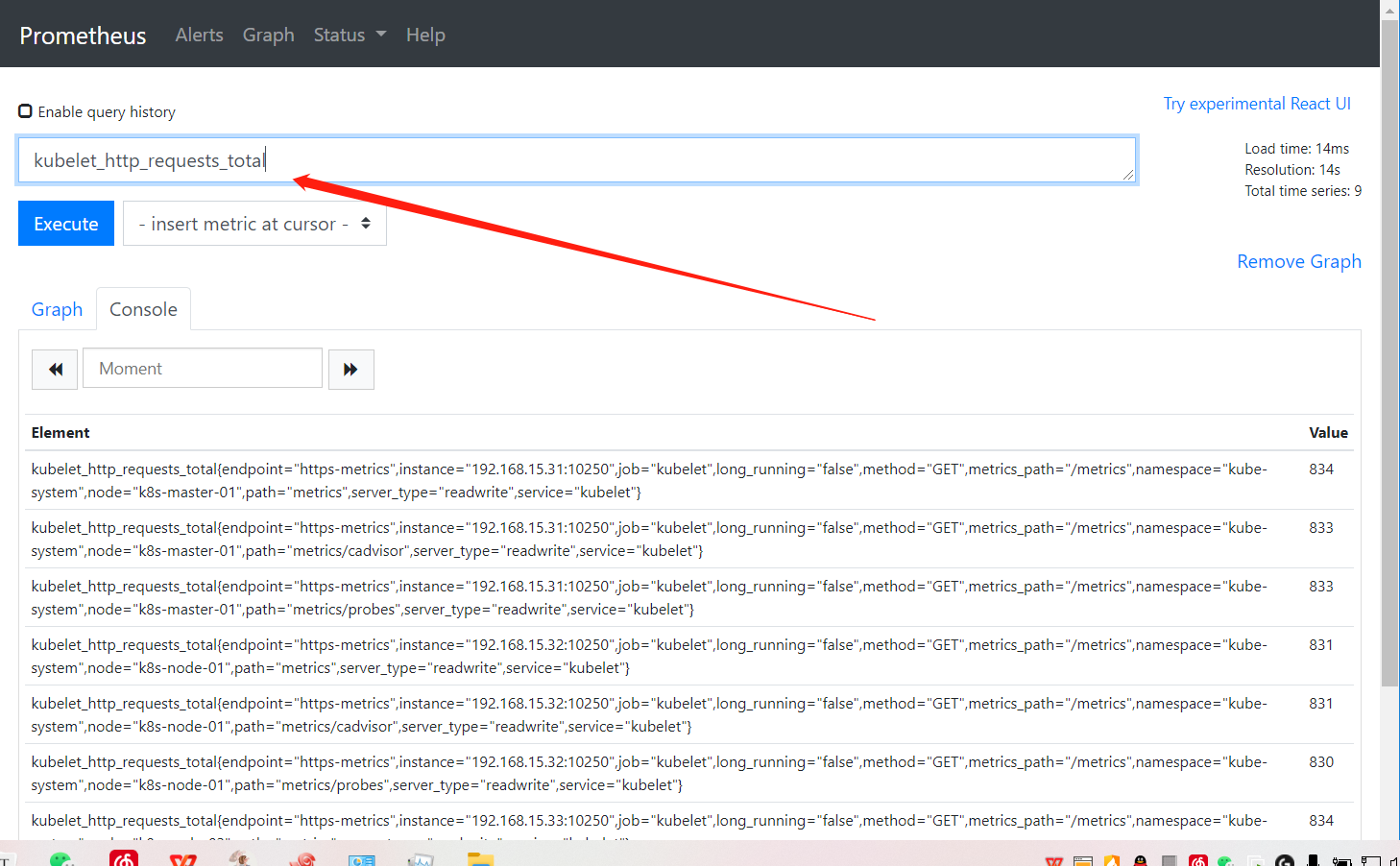
[5m] : 5分钟以内的数据
s:seconds
m:minutes
h:hours
d:days
w:weeks
y:years
Offset :查看多少分钟之前的数据
kubelet_http_requests_total[5m]
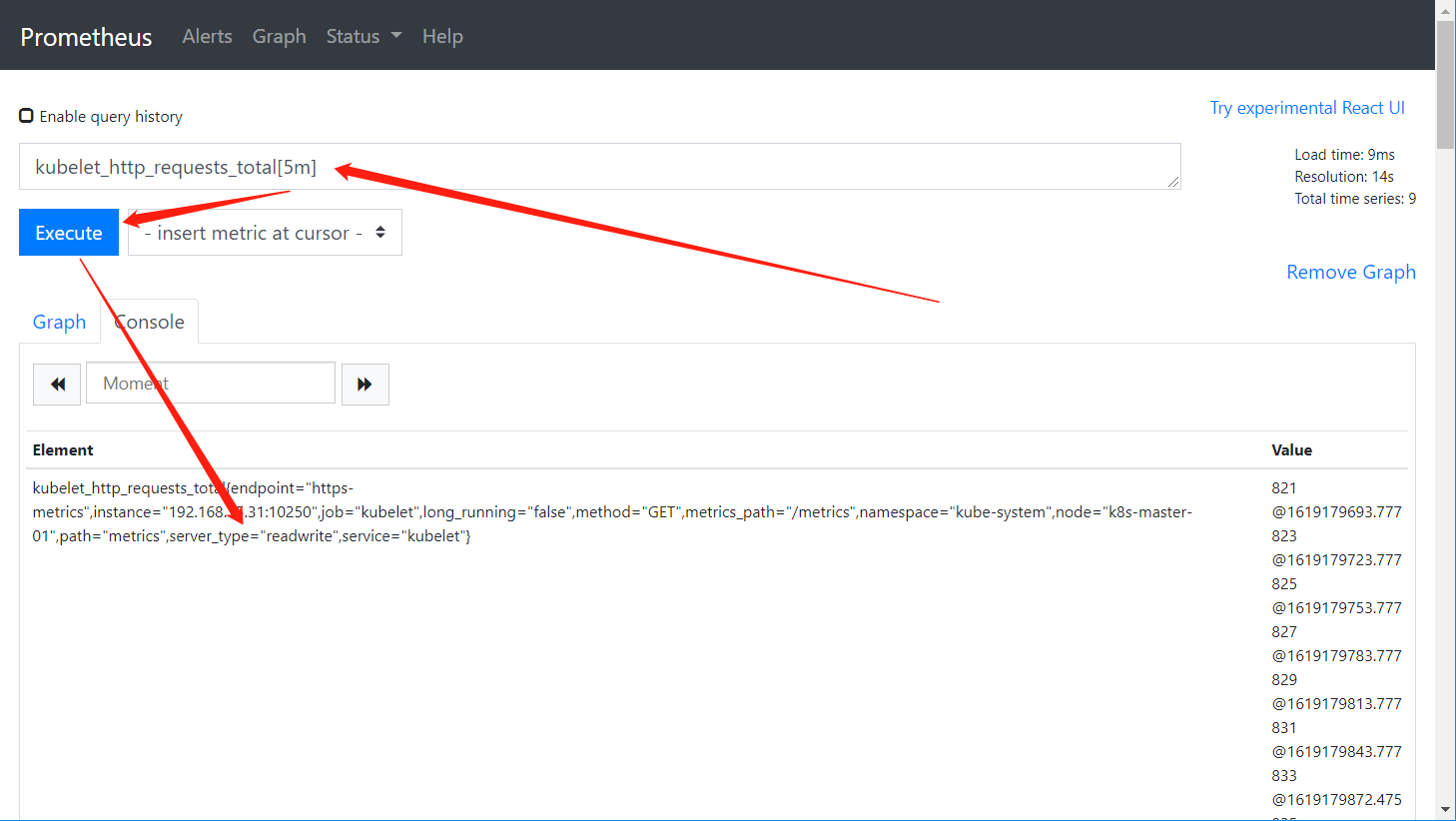
kubelet_http_requests_total offset 30m
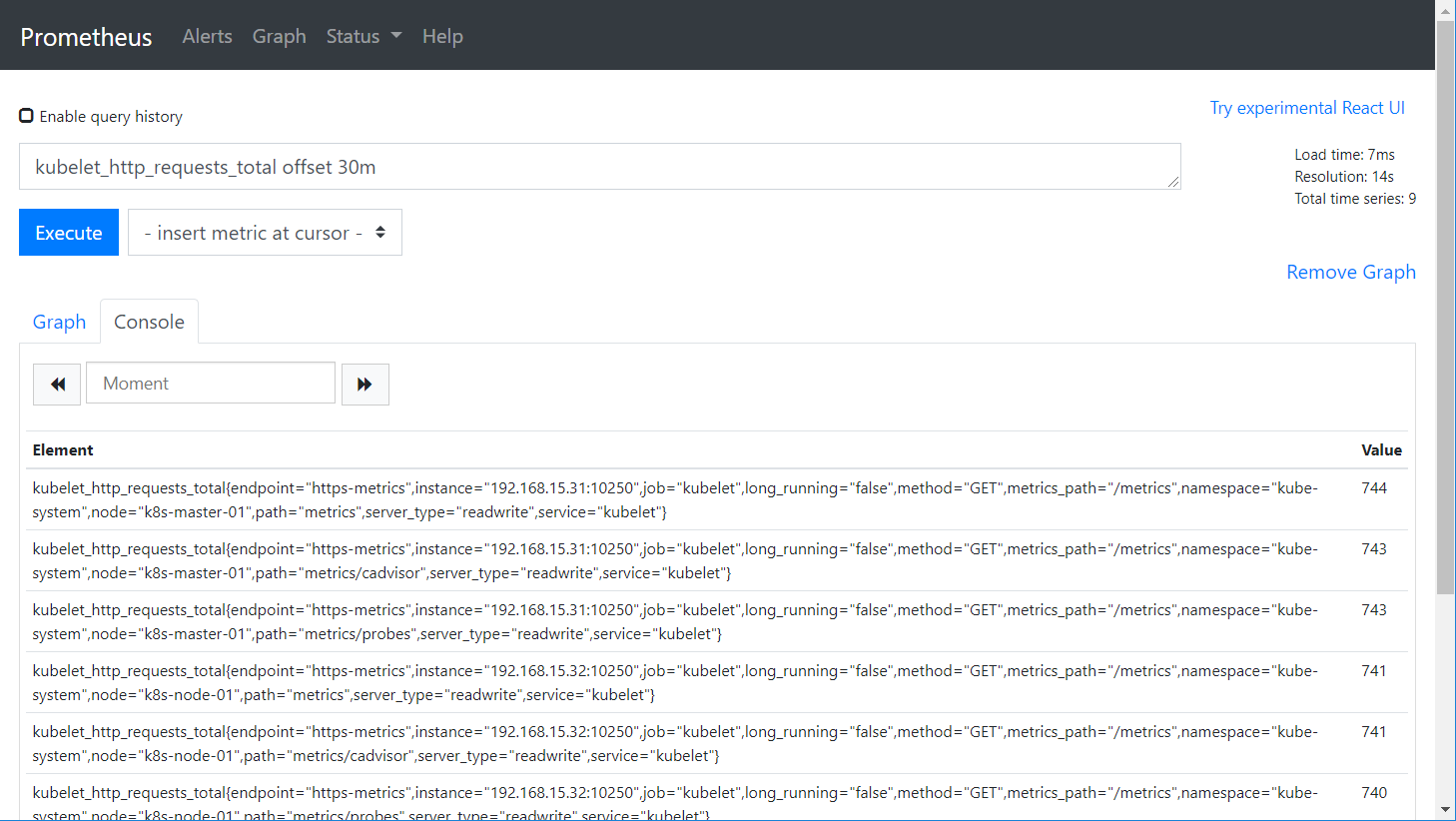
kubelet_http_requests_total [5m] offset 30m
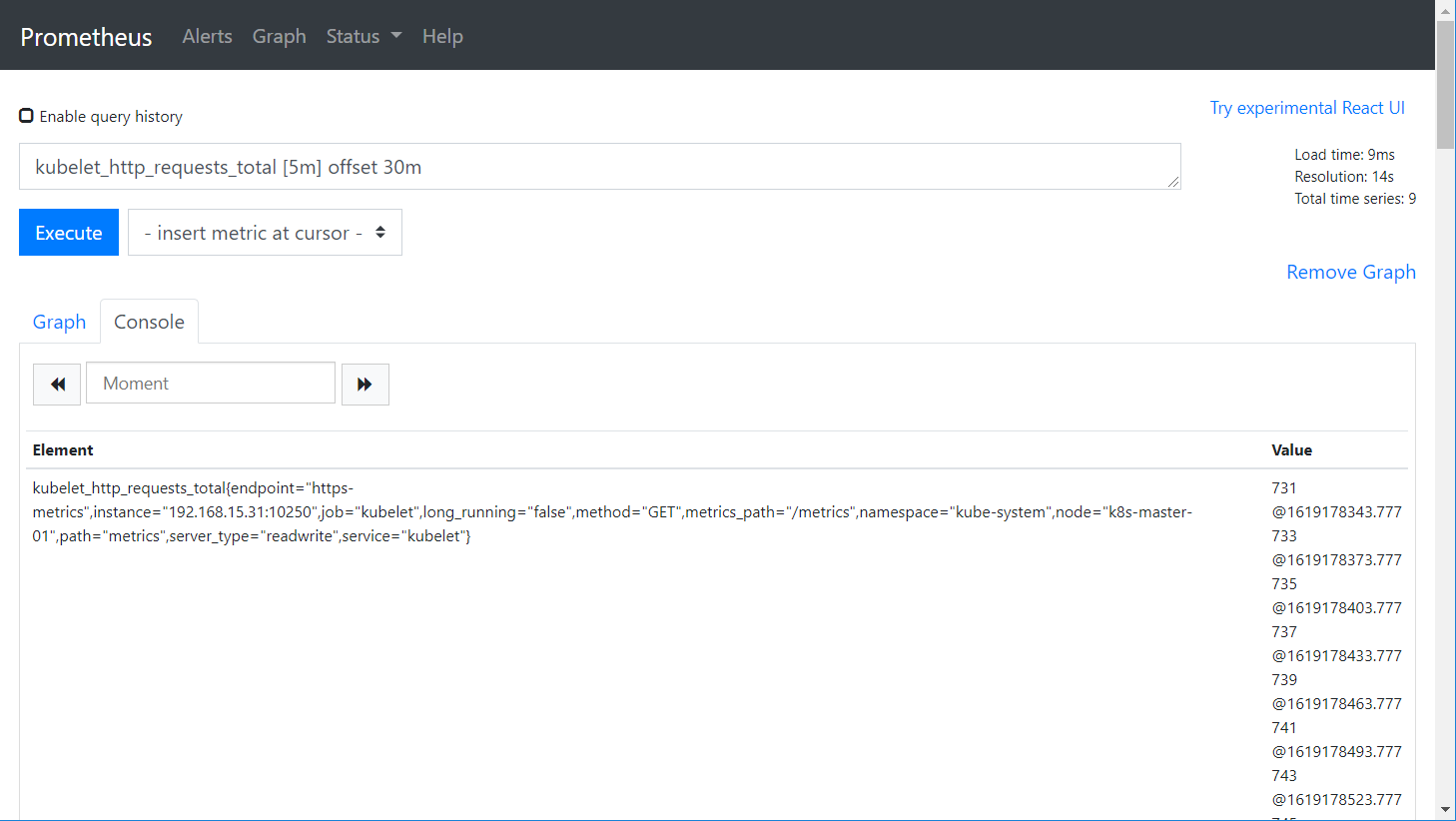
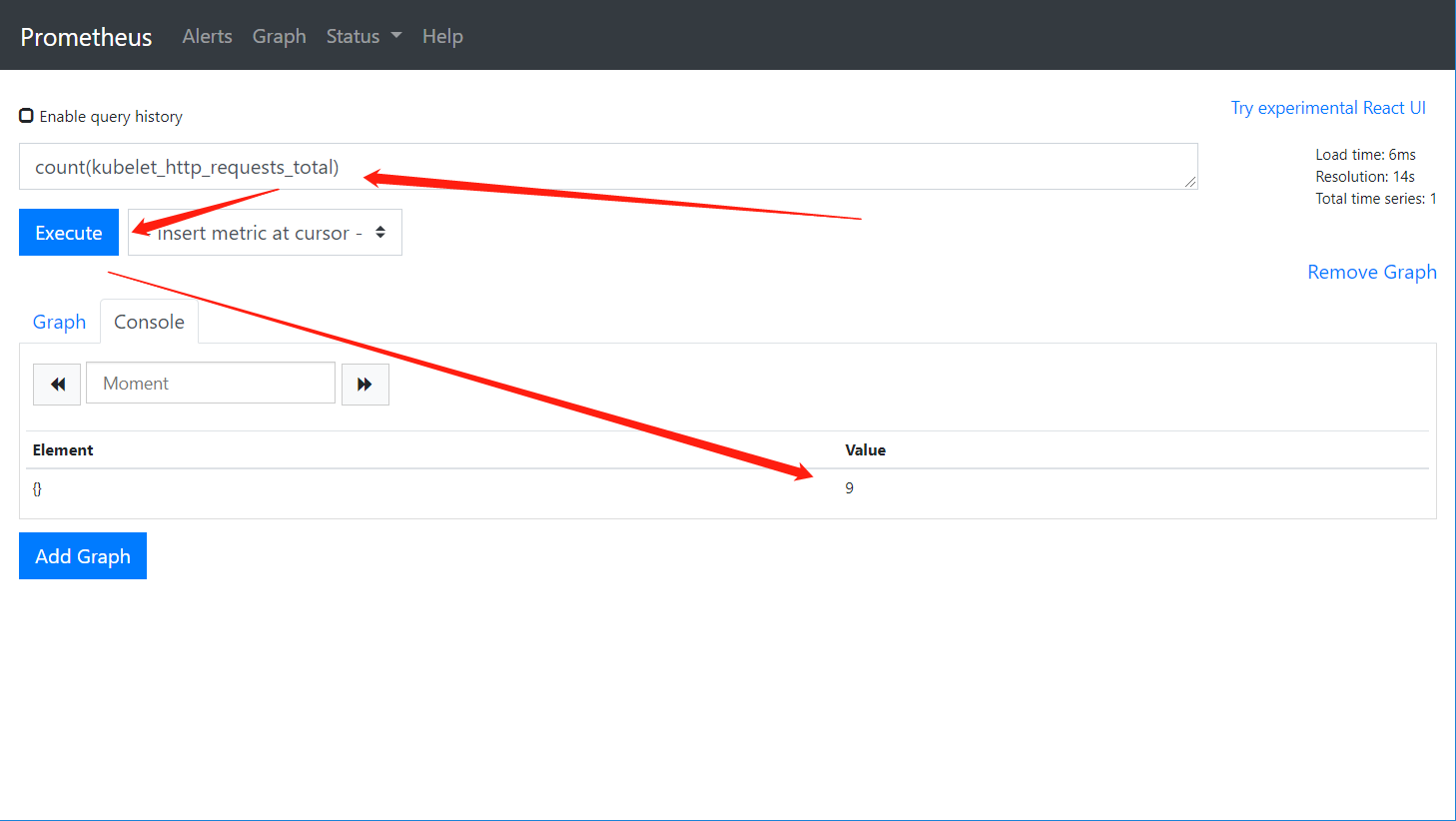
count(kubelet_http_requests_total)
#count 统计监控项的job
prometheus的底层数据模型有四种。
Counter:---->只增不减的计数器
cpu运行时间
http请求数
gauge: ---->可憎可减的
系统负载情况
内存使用情况
Histogram & Summary --->用于统计分析样本的分布情况
http平均响应时间
Prometheus 存储的是时序数据,而它的时序是由名字和一组标签构成的,其实名字也可以写出标签的形式。
container_spec_cpu_quota{container="config-reloader"}
# 或
container_spec_cpu_quota{container=~"config-reloader"}
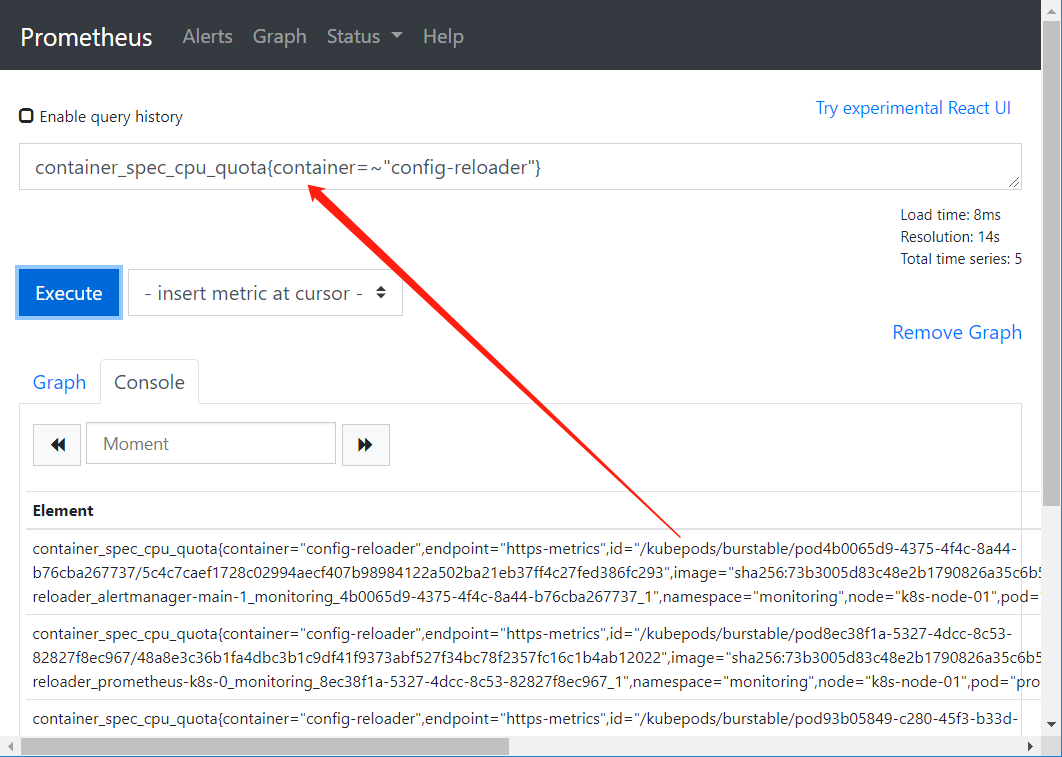
container_spec_cpu_quota{container!="config-reloader"}
container_spec_cpu_quota{container=~"config.*"}
# 或
container_spec_cpu_quota{container=~".*re.*"}
container_spec_cpu_quota{container!~".*re.*"}
# 或
container_spec_cpu_quota{container!~".*config.*"}
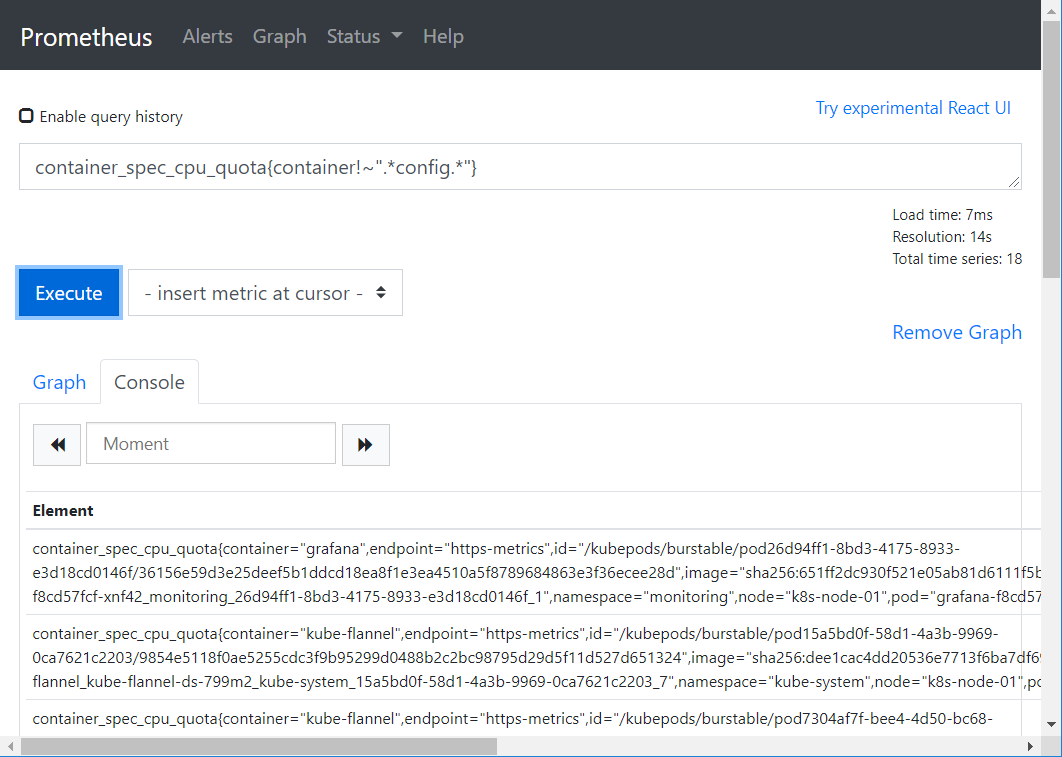
container_spec_cpu_quota{container=~"kube-flannel|.*config.*"}
https://prometheus.io/docs/prometheus/latest/querying/operators/
+ (添加)
- (减法)
* (乘法)
/ (除法)
% (取模)
^ (幂)
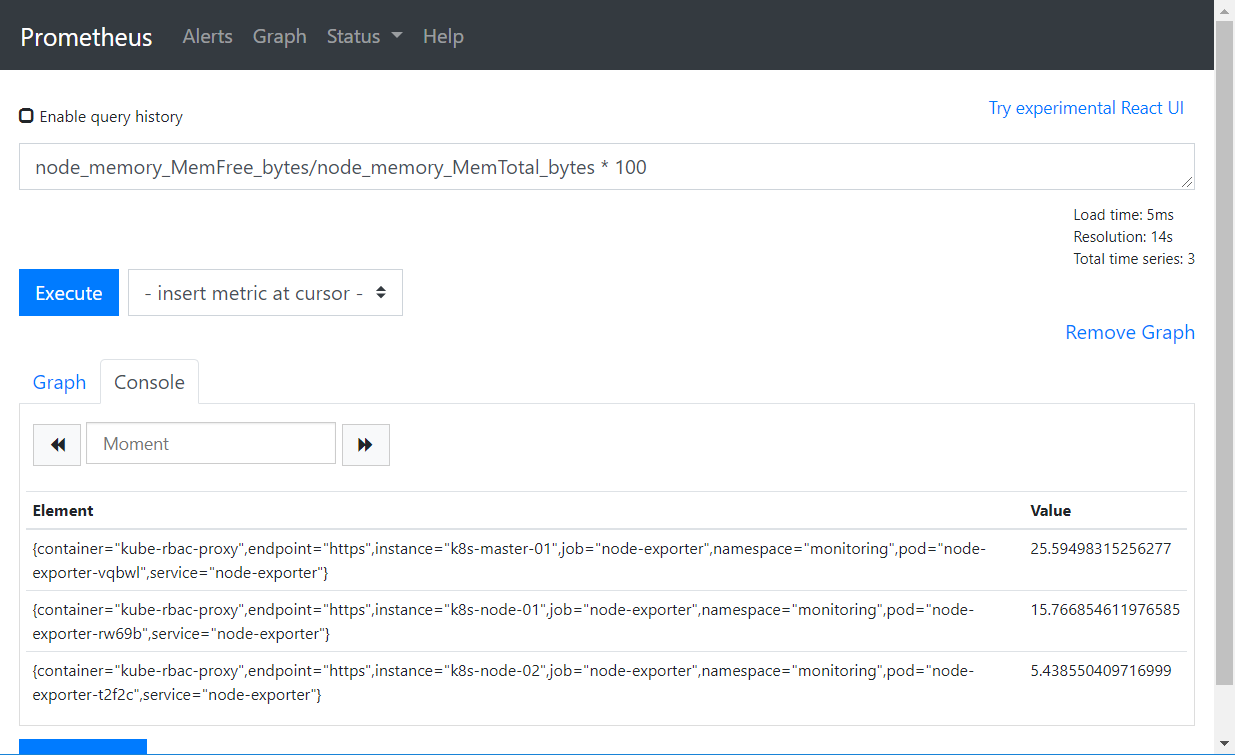
计算内存使用率
node_memory_MemFree_bytes/node_memory_MemTotal_bytes * 100
== (等于)
!= (不等于)
> (大于)
< (小于)
>= (大于等于)
<= (小于等于)
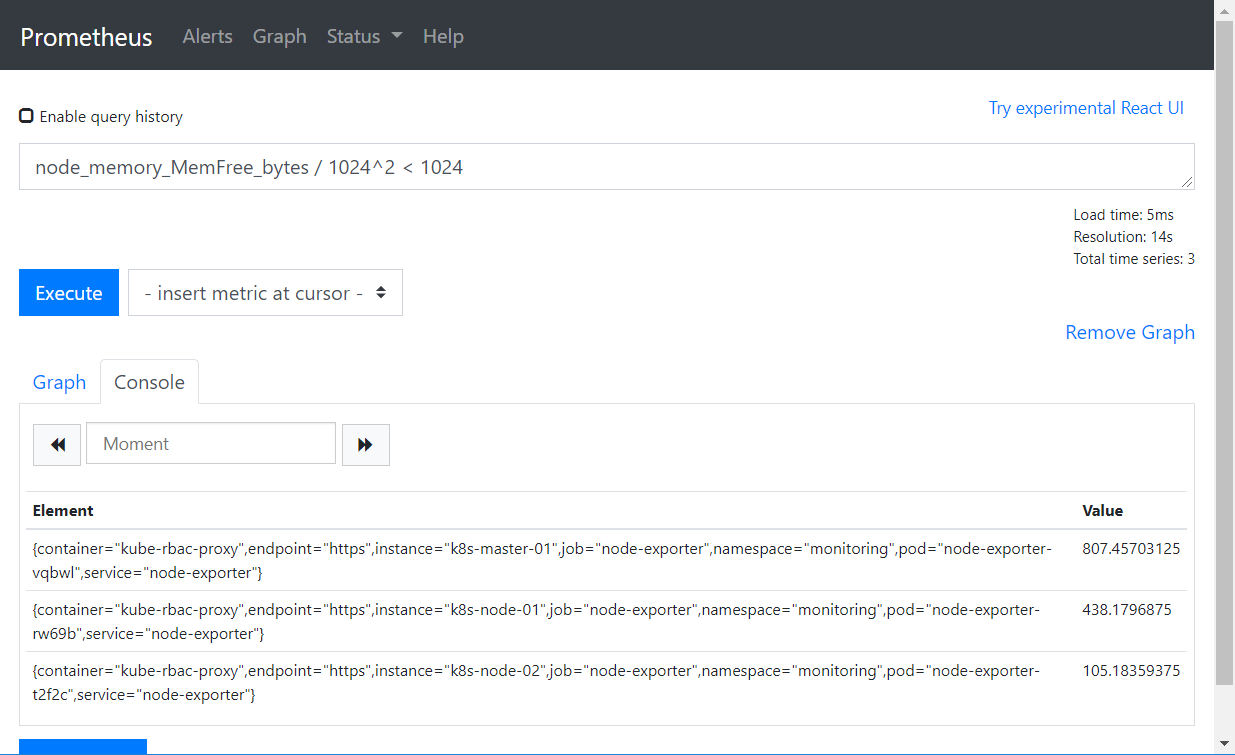
计算内存小于1G
node_memory_MemFree_bytes / 1024^2 < 1024
and 且
or 或
unless 非
且
alertmanager_cluster_messages_sent_total > 440 and alertmanager_cluster_messages_sent_total < 500
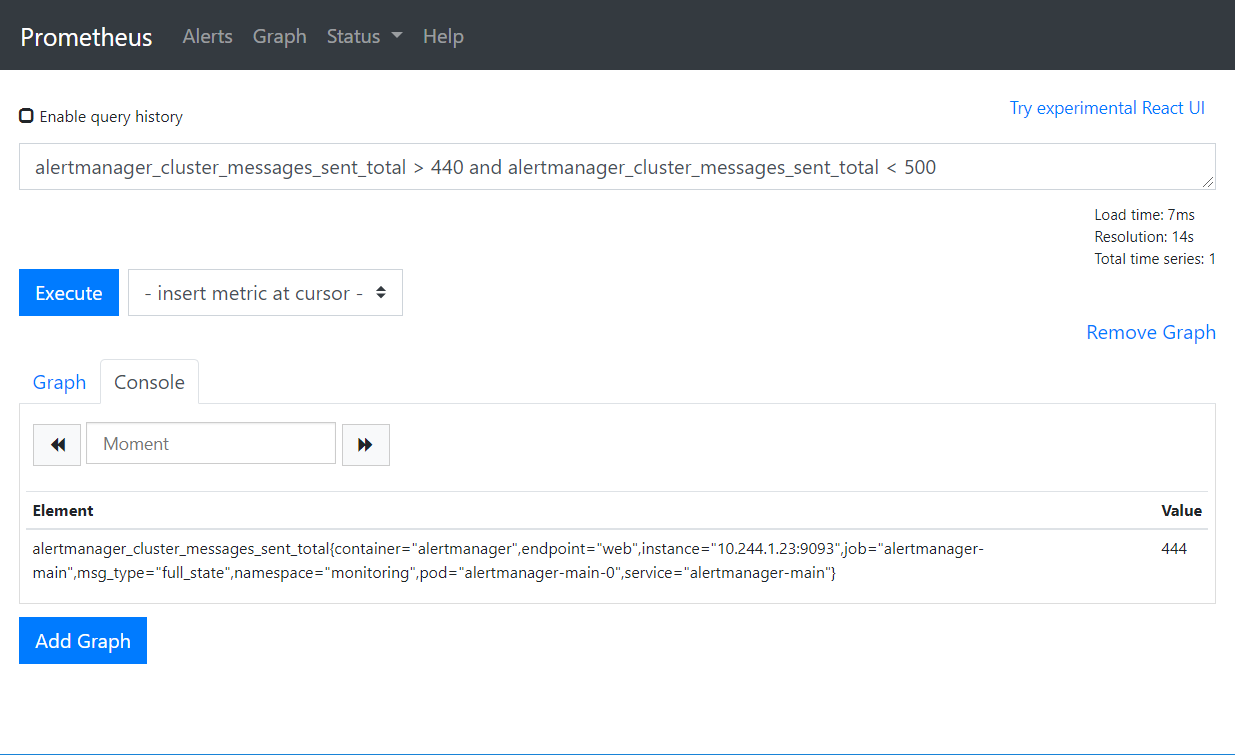
或
alertmanager_cluster_messages_sent_total > 440 or alertmanager_cluster_messages_sent_total < 400
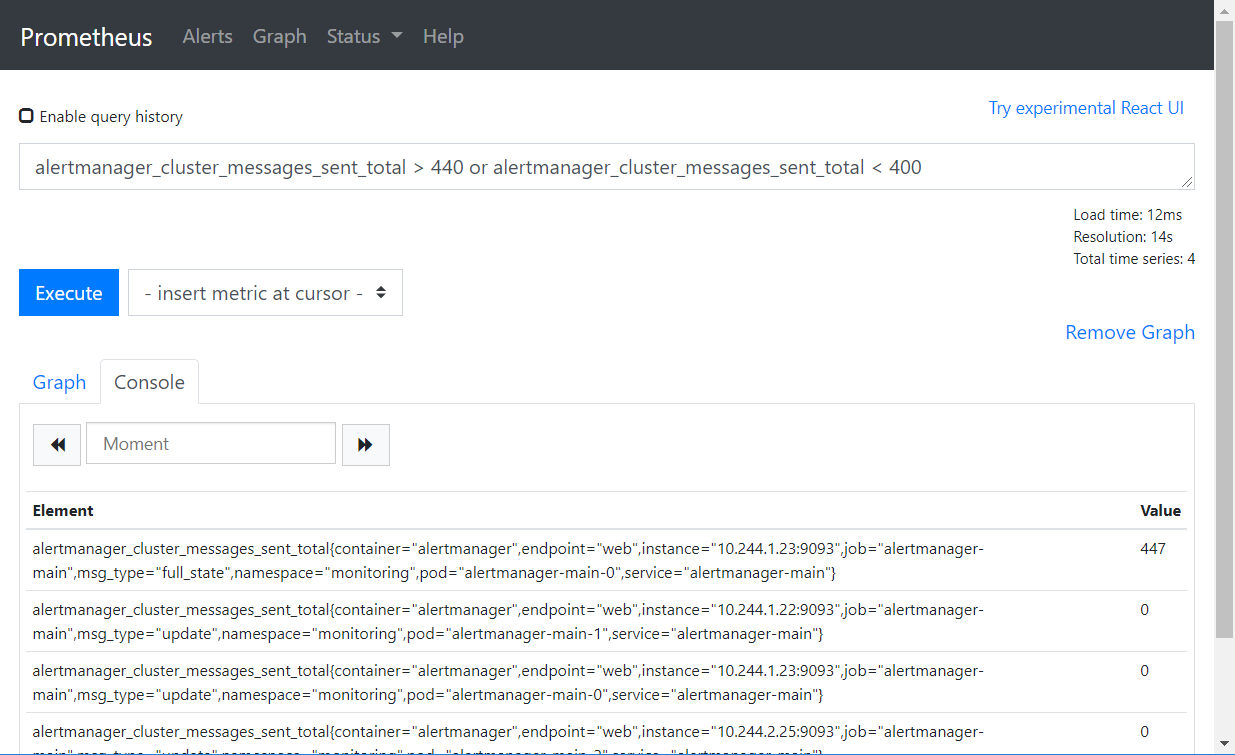
非
alertmanager_cluster_messages_sent_total > 440 unless alertmanager_cluster_messages_sent_total < 400
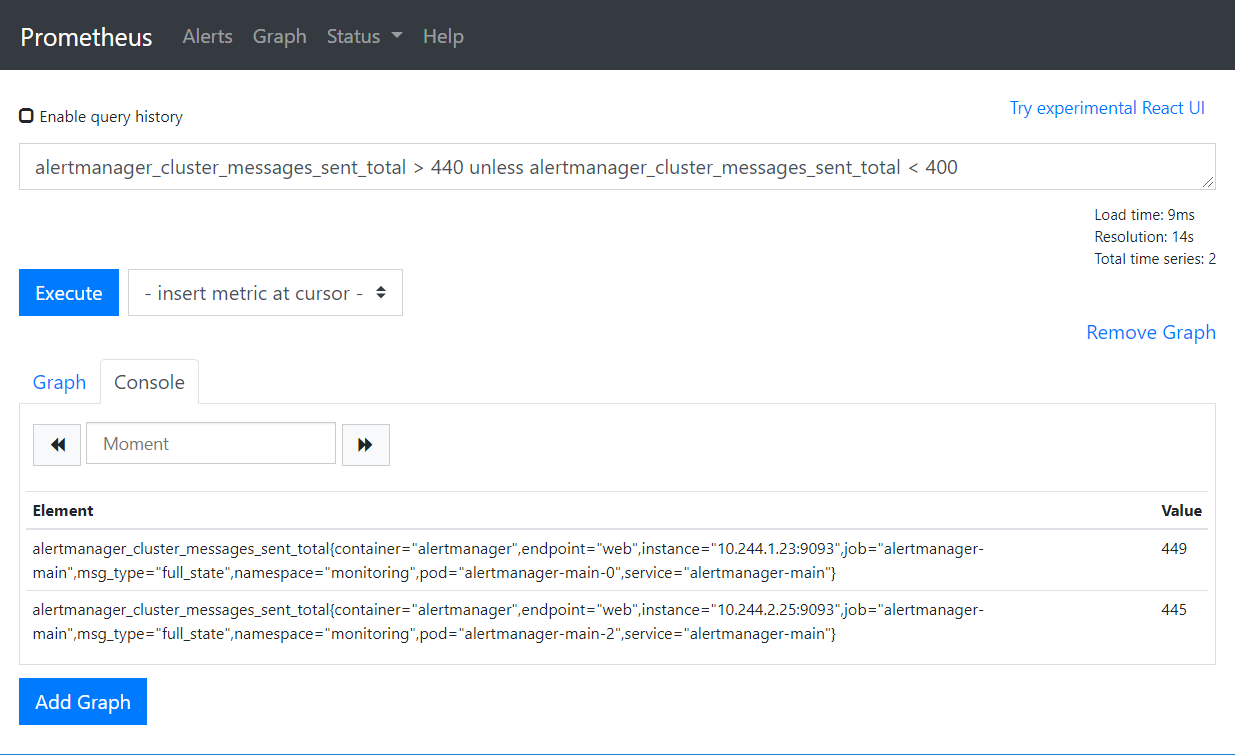
sum (求和)
min (求最小值)
max (求最大值)
avg (求平均值)
group (结果向量中的所有值均为1)
stddev (计算标准差)
方差的算术平方根
stdvar (计算标准方差)
count (统计元素的数量)
count(alertmanager_cluster_messages_sent_total)
count_values (统计相同值的元素的数量)
bottomk (获取元素最小的k个元素)
bottomk(2,alertmanager_cluster_messages_sent_total)
topk (获取元素最大k个元素)
topk(2,alertmanager_cluster_messages_sent_total)
quantile (在整个尺寸上计算φ分位数(0≤φ≤1))
quantile(0.3,alertmanager_cluster_messages_sent_total)
sum(alertmanager_cluster_messages_sent_total)
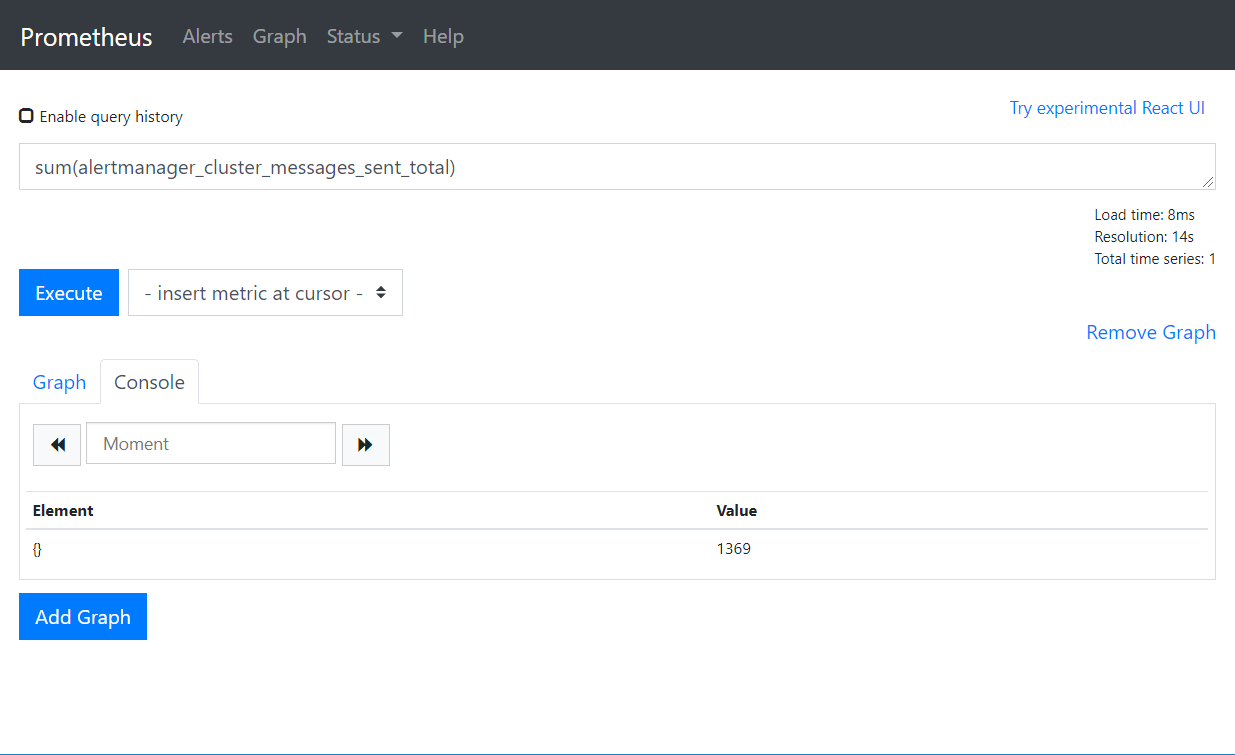
min(alertmanager_cluster_messages_sent_total)
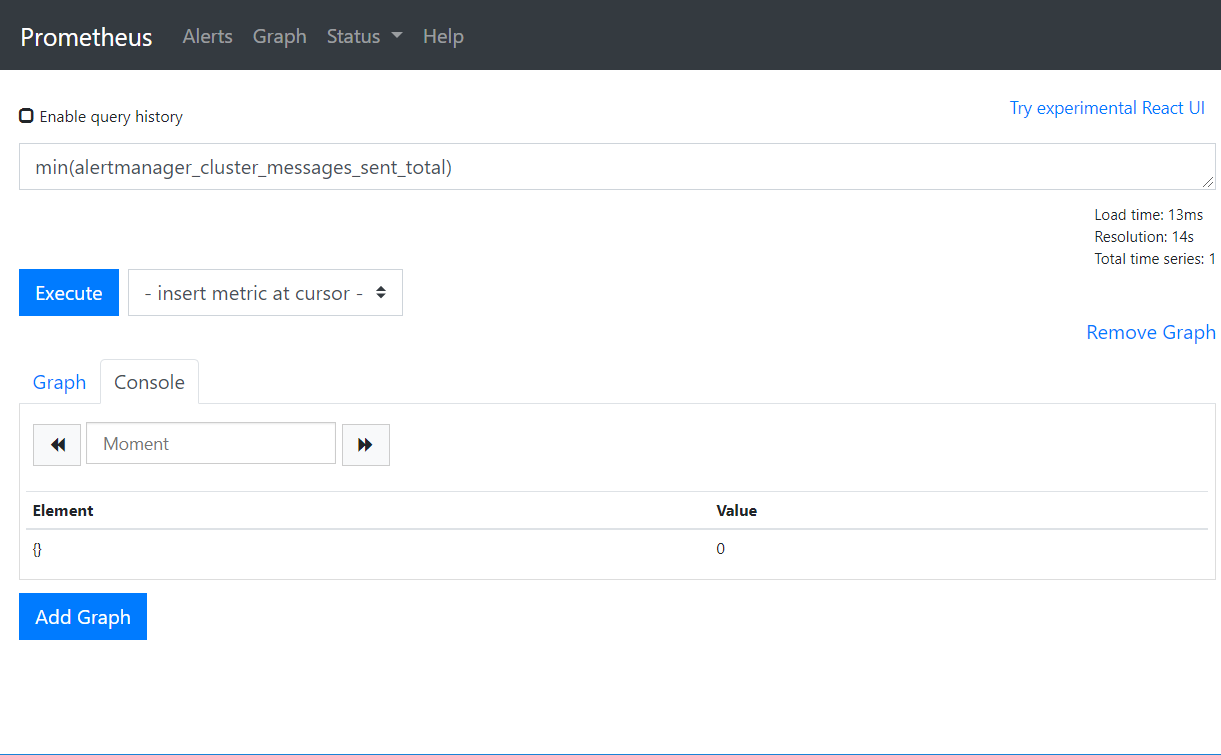
max(alertmanager_cluster_messages_sent_total)
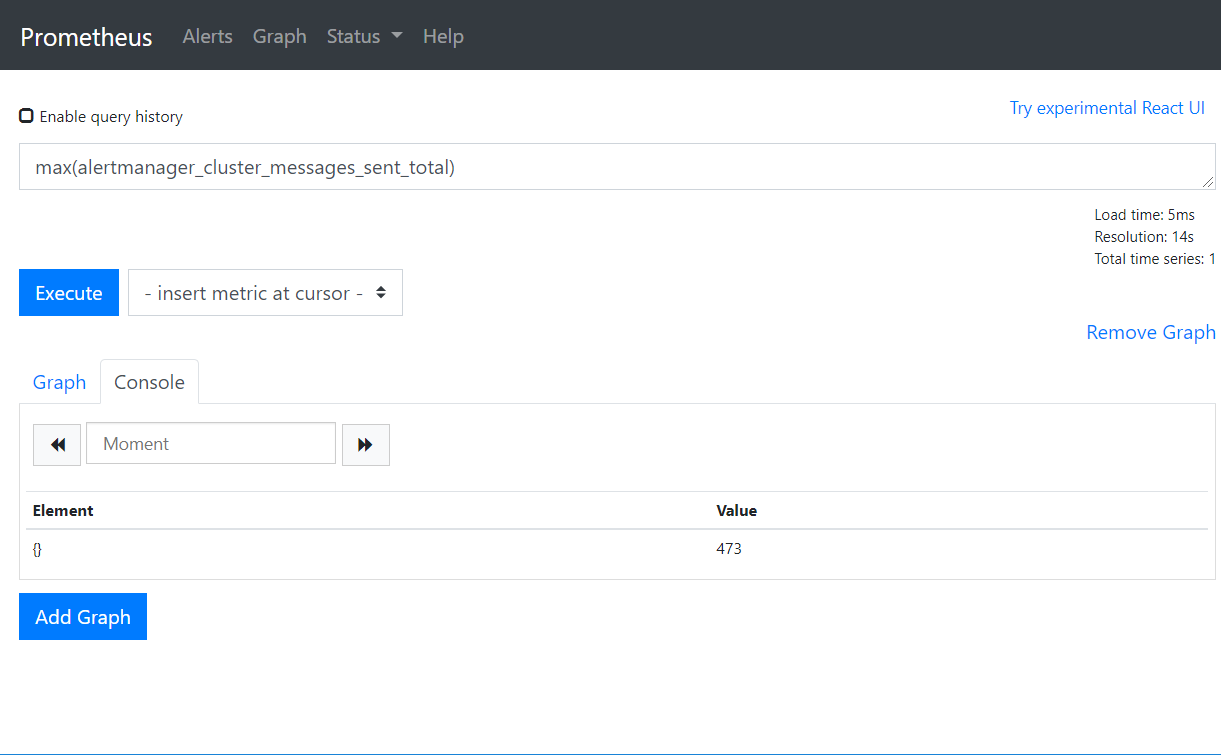
avg(alertmanager_cluster_messages_sent_total)
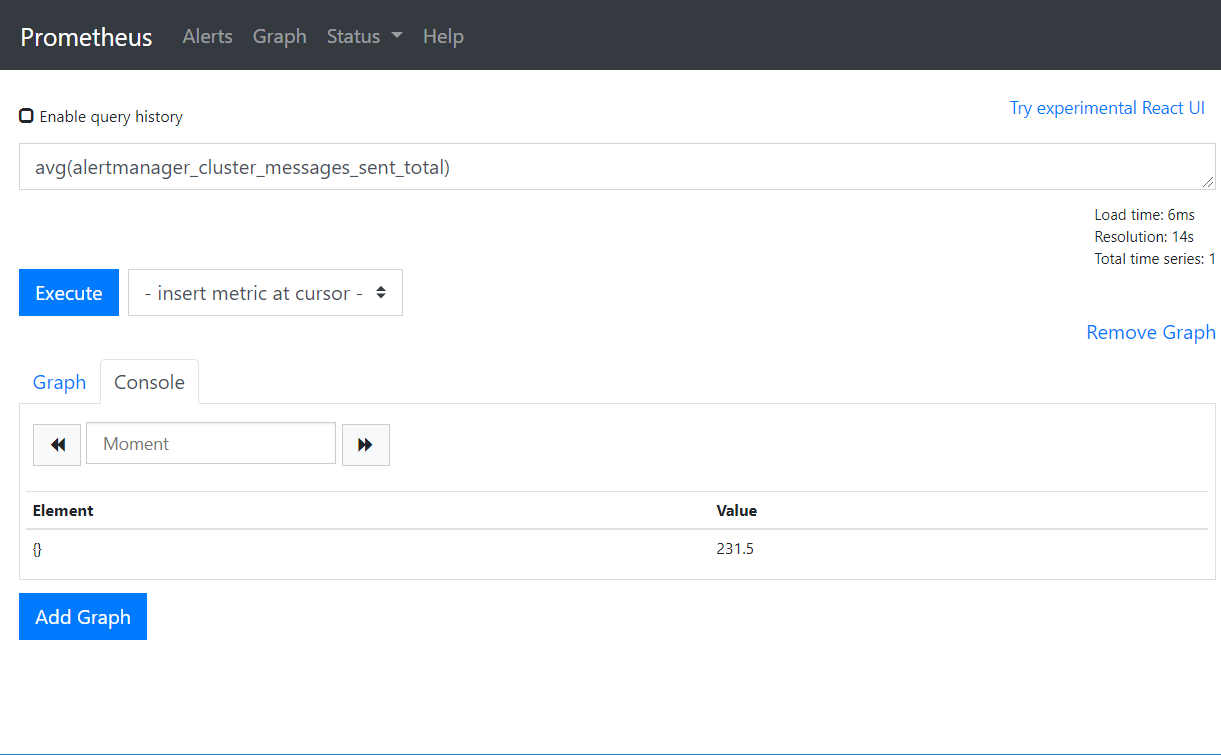
这里就不一一列举了
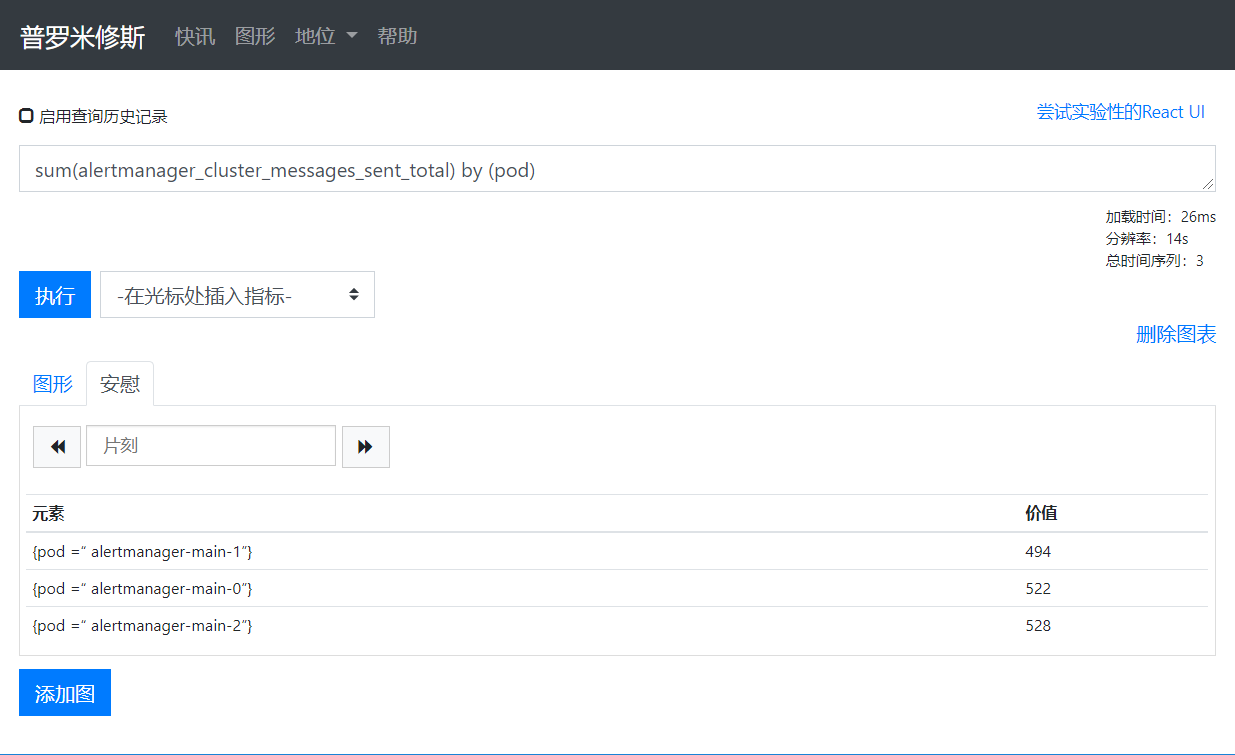
根据不同的标签查询
sum(alertmanager_cluster_messages_sent_total) by (pod)
^
*,/,%
+, -
==,!=,<=,<,>=,>
and, unless
or
运算符号与计算对象要以空格分开
和数学中一样,()可以代表一个整体,优先计算
https://prometheus.io/docs/prometheus/latest/querying/functions/
increase(v range-vector) 函数获取区间向量中的第一个和最后一个样本并返回其增长量返回区间向量中每个时间序列过去 5 分钟内 HTTP 请求数的增长数:
increase(http_requests_total{job="apiserver"}[5m])
计算磁盘的IO延迟:
increase(node_disk_io_time_ms{host_ip=~".+"}[2m]) / (increase(node_disk_reads_completed[2m]) + increase(node_disk_writes_completed[2m]
rate(v range-vector) 函数可以直接计算区间向量 v 在时间窗口内平均每秒增长速率返回区间向量中每个时间序列过去 5 分钟内 HTTP 请求数的每秒增长率:
rate(http_requests_total[5m])
irate(v range-vector) 函数用于计算区间向量的增长率,但是其反应出的是瞬时增长率。irate 函数是通过区间向量中最后两个两本数据来计算区间向量的增长速率,它会在单调性发生变化时(如由于采样目标重启引起的计数器复位)自动中断。
这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过irate函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
irate 只能用于绘制快速变化的计数器,在长期趋势分析或者告警中更推荐使用 rate 函数。因为使用 irate 函数时,速率的简短变化会重置 FOR 语句,形成的图形有很多波峰,难以阅读。
返回区间向量中每个时间序列过去 5 分钟内最后两个样本数据的 HTTP 请求数的增长率:
irate(http_requests_total{job="api-server"}[5m])
delta(v range-vector) 的参数是一个区间向量,返回一个瞬时向量。它计算一个区间向量 v 的第一个元素和最后一个元素之间的差值。返回过去两小时的 CPU 温度差:
delta(cpu_temp_celsius{host="zeus"}[2h])
sort排序sort(alertmanager_cluster_messages_sent_total)
sort_desc倒叙sort_desc(alertmanager_cluster_messages_sent_total)
ceil向上取整ceil(node_filesystem_free_bytes/1024^2)
floor向下取整floor(node_filesystem_free_bytes/1024^2)
round四舍五入round(node_filesystem_free_bytes/1024^2)
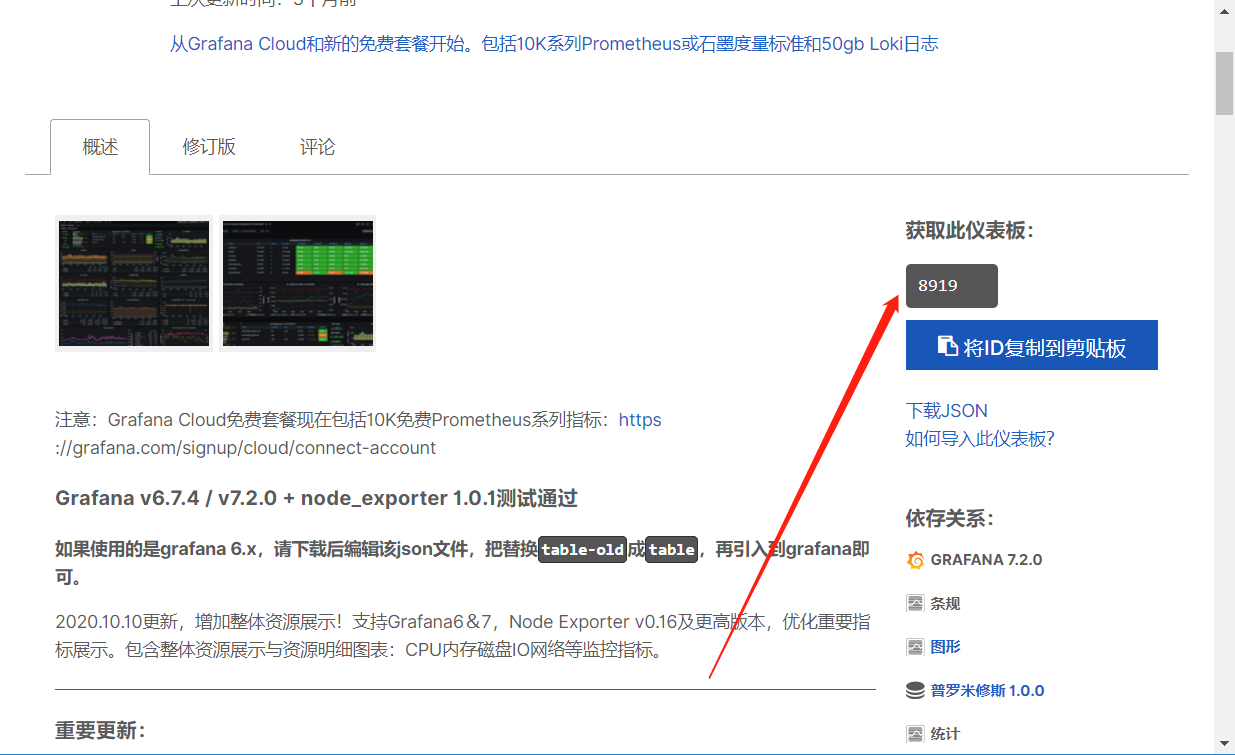
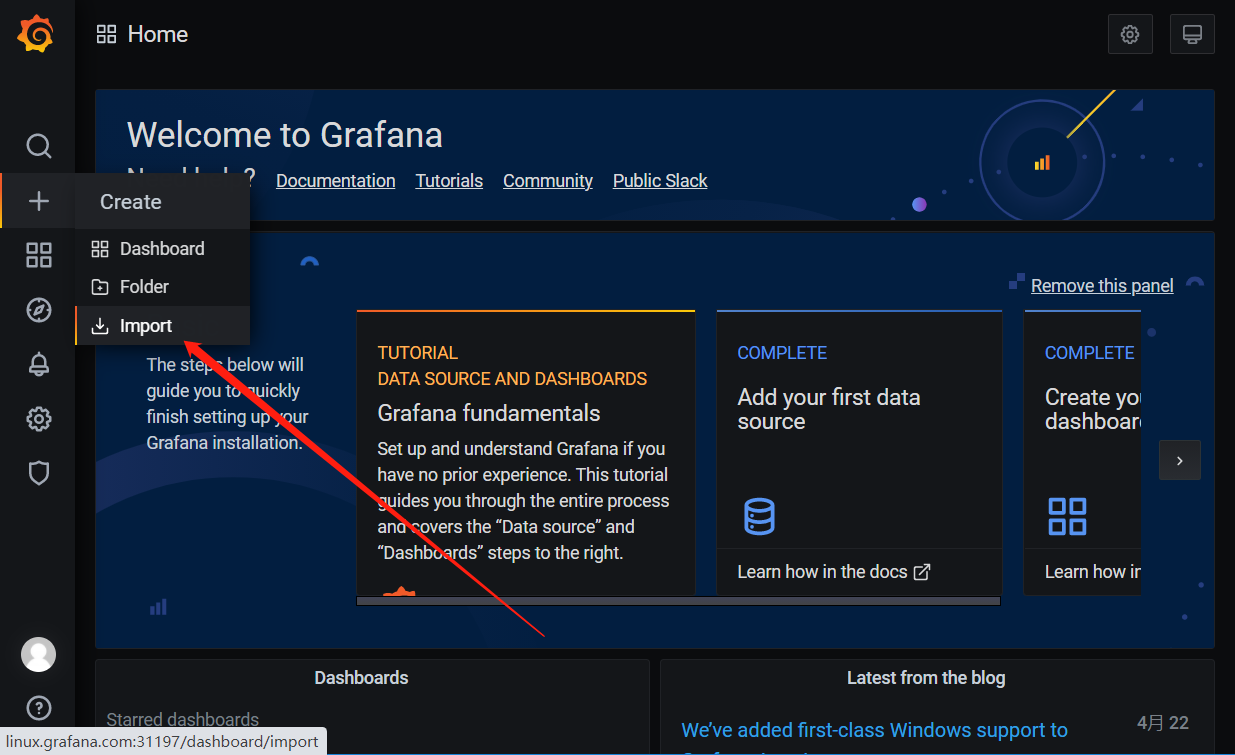
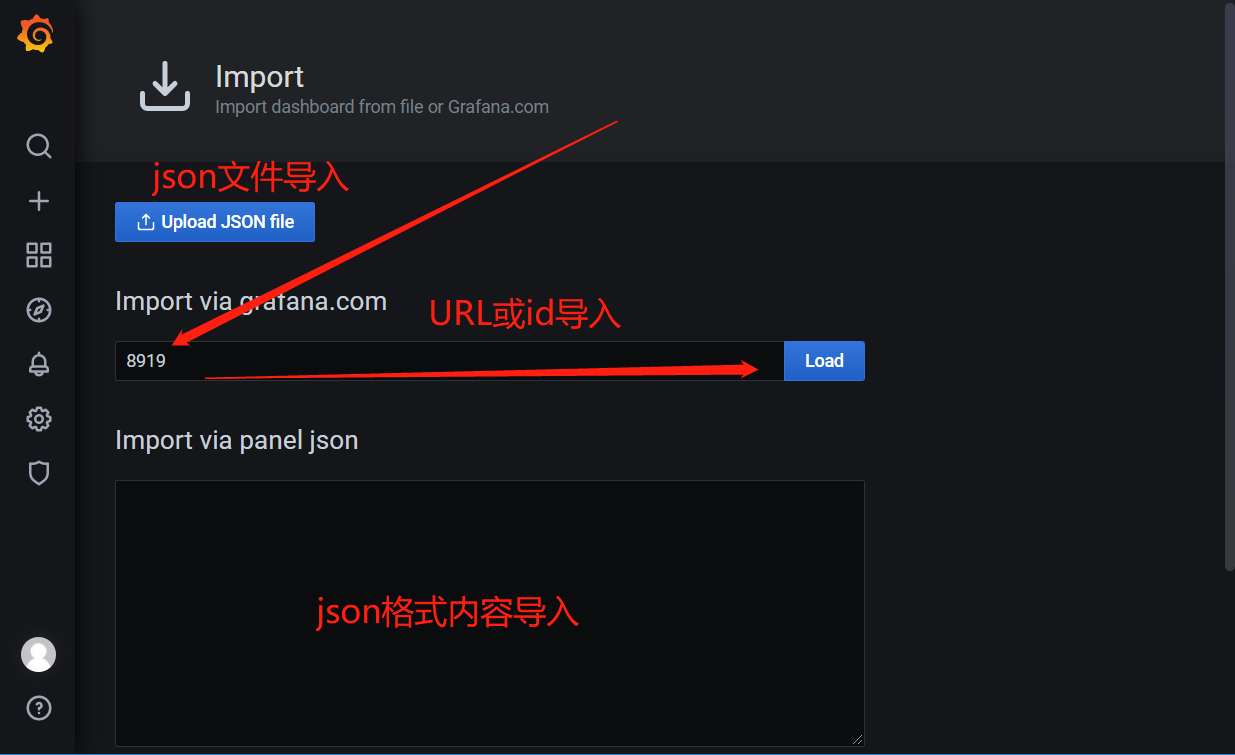
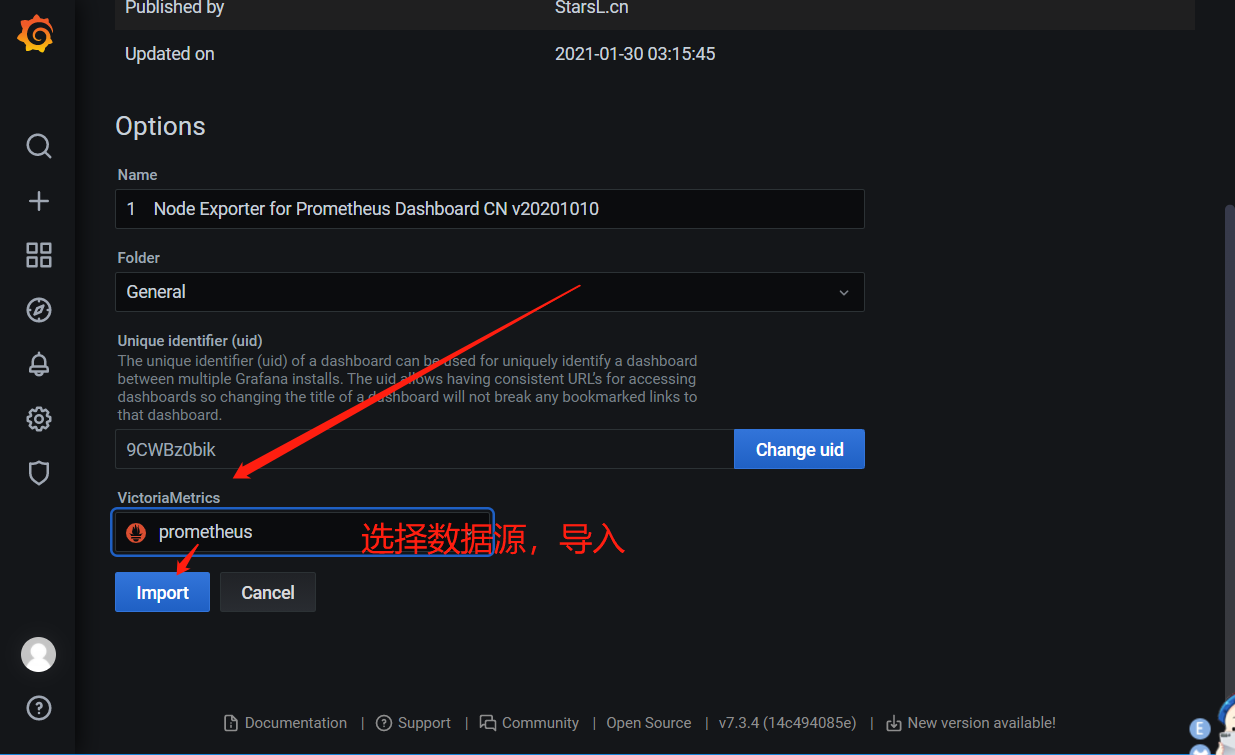
https://grafana.com/grafana/dashboards/